.png)
实验语音学常用软件入门•SPSS简介及T检验
1.概论
为什么要学习SPSS?
同一研究,不同方法,不同叙述
案例:两个城市对于某一元音的不同发音。
在没有统计分析的情况下,研究者主要通过听觉评估、文字记录来分析和描述数据。例如,研究者可能会在现场记录下他们观察到的某个元音在两个地区发音的主观差异,并依靠这些描述来支持其论点。其论述可能是这样的:
城市A的方言中,该元音的发音更接近于[i]音,而在城市B的方言中,则更倾向于[e]音。
这种分析主要依赖于个别样本的描述性观察,只靠口耳现场记录,而不是广泛的数据集,具有偶然性,难以令人信服。如果不是语音学资深的研究者,那么这样的叙述就更难让人信服。
如果该研究使用声学分析软件(如Praat)来分析录制的语音样本,测量元音的声学特征,如第一共振峰频率(F1)和第二共振峰频率(F2),并调查了更多的发音人,并且拥有了一个数据集。例如下表的数据集(局部):
| City | Participant | F1 | F2 |
|---|---|---|---|
| A | 1 | 524.8357077 | 1532.408397 |
| A | 2 | 493.0867849 | 1461.491772 |
| A | 3 | 532.3844269 | 1432.3078 |
| B | 4 | 576.1514928 | 1561.167629 |
| B | 5 | 488.2923313 | 1603.099952 |
| …… | …… | …… | …… |
即使有了可观的数据,但却未将数据进行进一步的统计分析,论述可能是这样的:
本研究初步探讨了城市A和城市B的方言差异,特别是关注了两地发音人x元音的发音特征。通过听觉评估和对发音人语音样本的分析,我们观察到城市A的发音人在某些元音发音上似乎与城市B的讲者有所不同。具体来说,城市A的发音人在发音时,该元音听起来较为闭合,这可能表明其第一共振频率(F1)较低。相比之下,城市B的发音人在相同元音的发音中,似乎更为开放,可能带有不同的声学特性。此外,虽然较难通过听感分辨,我们可以注意到,城市A发音人在某些情况下的元音发音中,其声音的某些质感可能指向第二共振频率(F2)的差异。
这段叙述主要依赖于观察和定性分析,仅仅基于主观评估和直观感受,与前面提供的统计分析结果相比,缺乏定量分析,缺乏必要的精确度和可靠性,缺少了定量化的证据和统计显著性的验证。
如果掌握了统计分析的方法,那么叙述就可以是这样的:
本研究通过对城市A和城市B的发音人x元音的第一共振频率(F1)和第二共振频率(F2)进行独立样本t检验,旨在探索两地方言在元音发音上的差异。结果显示,两个城市在F1值上存在显著差异(t = -6.08, p < 0.001),表明城市A的发音人在特定元音的发音上,与城市B的发音人相比,F1频率显著更低。此外,F2值的比较也揭示了两个城市之间的显著差异(t = 2.45, p < 0.05),这表明与城市B相比,城市A的发音人在该元音的发音上F2频率显著更高。这些结果支持了我们的假设,即不同地区的发音人在元音发音上存在显著的声学差异,从而反映了xx地区方言的特征。
毫无疑问,这样的叙述会为你的论文增光添彩,一个不懂统计的人也会觉得高大上了起来,但是使用统计方法的确是一种科学的研究方式,并且有助于发现肉眼观察所不能得到的规律与结论。
SPSS简介
SPSS,全称是Statistical Package for the Social Sciences,翻译为社会科学统计软件包。SPSS最初是为社会科学领域设计的,用于数据分析和统计建模。该软件提供了广泛的统计分析工具,使研究人员能够对各种类型的数据进行分析。
以下是SPSS的一些主要特点和功能:
- 数据管理: SPSS允许用户轻松导入、编辑和管理数据。用户可以进行数据清理、缺失值处理和变量转换等操作。
- 统计分析: SPSS提供了丰富的统计分析工具,包括描述性统计、推断统计、相关分析、回归分析、方差分析、聚类分析等。这些工具能够帮助用户深入了解数据的特征和关系。
- 图形展示: SPSS支持生成各种图表和图形,如柱状图、折线图、散点图等,以便用户更直观地呈现数据分布和趋势。
- 报告输出: SPSS能够生成专业的报告,包括统计表格、图形和解释,方便用户将分析结果分享给其他人。
- 代码语法和可视化界面两种操作方式: SPSS可以通过可视化界面进行操作,也可以使用语法进行命令式的操作。这使得用户可以选择适合自己习惯的方式来使用软件。
SPSS在社会科学、市场研究、医学研究等领域广泛应用,它为研究人员提供了一个强大的工具,帮助他们进行数据分析、模型建立和结果解释。虽然最初是为社会科学设计的,但由于其灵活性和广泛的应用范围,SPSS现在也被其他领域的研究人员广泛采用。
界面概述
- 起始界面:SPSS软件的起始界面简洁直观,提供了开始新项目或打开已有项目的选项。可以通过“新建”选择创建一个新的数据文件,或者通过“打开”选择现有的数据文件。
- 主菜单:位于软件窗口的顶部,包含一系列关键菜单,如“文件”、“编辑”、“数据”、“变量”、“分析”、“图表”、“窗口”等。这些菜单项是SPSS软件的核心控制中心,使用户能够快速访问不同功能区域。

- 数据视图:用户可以直接查看和编辑实际的数据表,每一行代表一个观测,每一列代表一个变量。
- 变量视图:允许用户定义每个变量的属性,如变量名称、类型、标签、测量水平等。这种分离的视图方式使数据管理更为灵活。

- 输出视图:执行统计分析后,结果将以表格、图表等形式自动生成在输出视图中。这个视图记录了整个分析过程和结果,为用户提供了一份可追溯的文档。用户可以随时查看输出,审查分析步骤,并将结果导出为不同格式的文件。
常见的描述性统计概念
- 平均值。平均值是一个数据集的中心趋势度量,通过将所有数据相加然后除以数据点的数量得到。例如,如果我们考察一个班级的学生考试分数,平均值可以帮助我们了解整体的表现水平。但要注意,平均值容易受到极端值的影响,因此在一些情况下,中位数可能更能反映数据的真实情况。
- 中位数。中位数是将数据集按大小排列后,位于中间位置的值。相对于平均值,中位数对于受到极端值干扰的数据更为稳健。在文科研究中,中位数可以用来了解数据的集中趋势,而不受异常值的过度影响。
- 众数。众数是数据集中出现频率最高的值。在文本研究中,众数可以帮助我们找到一篇文章中最常见的单词,这有助于分析作者的写作风格和关键主题。
- 标准差。标准差是衡量数据集离散程度的指标。通过标准差,我们可以了解数据集中的值与平均值的差异。在文科领域,标准差可以帮助我们理解一个文本中词语使用的变化程度,从而洞察其风格和结构的多样性。
- 四分位数是描述性统计中的一种常用指标,用于描述数据集的分布情况。四分位数将数据集分成四等份,具体来说,它将数据分成三个点,这三个点将数据分为四个部分:
- 第一四分位数 (Q1):是数据集中最小的 25% 的值。它是数据集的下四分之一点。Q1 划分了数据集的较低部分。
- 第二四分位数 (Q2):也就是中位数,将数据集分为两半。50% 的值在中位数的下方,50% 的值在上方。中位数是数据集的中心位置。
- 第三四分位数 (Q3):是数据集中最小的 75% 的值。它是数据集的上四分之一点。Q3 划分了数据集的较高部分。
T检验的相关概念
在语言学研究中,我们经常需要比较两组样本的差异,例如探讨两个不同语言学习方法的效果,两组学生在同一语言活动中的反应情况,而T检验是一种常用的统计方法,可以帮助我们判断两组样本在某一方面是否存在显著性差异。
简而言之,T检验是一种用于比较两组样本均值是否存在显著差异的统计方法。
T检验的主要类型
- 独立样本T检验:用于比较两组独立样本的均值。
- 单样本的T检验:推断样本的平均值和指定的检验值之间的差异是否显著。
- 配对样本的T检验:独立样本T检验的数据来源是独立的样本,如同一个班级中男生和女生的成绩是否有差异;而配对样本T检验的范围是同一组对象,例如一个班级中的女生第一次月考和第二次月考的成绩是否有差异。
T检验的假设
在进行T检验时,通常会提出两个假设,分别是零假设(H0)和备择假设(H1)。
- 零假设(H0):这是我们想要进行推翻的假设。它通常表明两组数据的平均值没有显著差异,或者说差异只是抽样误差导致的。在T检验中,零假设通常表示两组数据的平均值相等。
- 备择假设(H1):这是我们想要验证的假设。它通常表明两组数据的平均值存在显著差异。备择假设可以是双侧的(表示两组数据的平均值不相等)或单侧的(表示其中一组数据的平均值比另一组大或小)。
在进行T检验后,根据实际计算得到的统计值和显著性水平(通常是α,例如0.05),我们会做出以下判断:
- 如果计算得到的p值小于设定的显著性水平α,则我们拒绝零假设,接受备择假设,认为两组数据的平均值存在显著差异。- 如果计算得到的p值大于等于设定的显著性水平α,则我们无法拒绝零假设,即无法得出两组数据平均值存在显著差异的结论。
T检验的条件
在进行T检验时,需要满足以下几个条件:
- 样本来自正态分布或样本容量足够大: T检验对样本来自正态分布的数据效果最好。如果样本容量较大(通常大于30),即使数据不完全符合正态分布,也可以进行T检验。当样本容量较小时,数据应尽可能接近正态分布。
- 方差齐性: T检验假定两个样本的方差相等。在进行T检验之前,通常需要进行方差齐性检验。如果两个样本的方差不相等,可能需要使用修正的T检验方法。
- 独立性: 进行独立样本T检验的两个样本应该是相互独立的。这意味着一个样本的观察结果不应该受到另一个样本的影响。对于其余类型的T检验则有不同的要求。
- 连续性数据: T检验适用于连续型数据,即数据是用于度量的,而不是分类的。
- 随机抽样: 样本应该是随机抽取的,以确保样本代表总体。
其中,正态性和方差齐性检验是需要进行在实际应用中,如果数据不满足以上所有条件,也可能进行T检验,但结果的解释和可信度可能会受到影响。此外,如果违反了某些条件,可能需要考虑使用其他统计方法来进行假设检验。
T值(T-statistic)
T值是用来衡量两组样本均值之间差异是否显著的统计量。T值的计算基于样本均值之间的差异和标准误差的比较。
-
T值的计算公式:
T = \frac{\bar{X}_1 - \bar{X}_2}{\sqrt{\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}}}其中, (\bar{X}_1) 和 (\bar{X}_2) 分别是两组样本的均值,(s_1^2) 和 (s_2^2) 分别是两组样本的方差,(n_1) 和 (n_2) 分别是两组样本的大小。
-
T值的解释:
-
如果T值较大,意味着两组样本的均值差异较大。
-
如果T值较小,可能是由于观察到的差异仅仅是由于随机因素导致的。
-
与显著性水平比较:
在进行假设检验时,我们将计算得到的T值与临界T值相比较,或者查找P值。如果T值较大,并且P值小于显著性水平(通常为0.05),我们就有足够的证据拒绝零假设。
P值的含义:
- 含义: P值是概率值,表示在零假设成立的情况下,观察到的统计量或更极端统计量的概率。
- 范围: P值的范围在0到1之间,通常以小数形式表示。越小的P值表示观察到的结果在零假设下发生的概率越小。
P值的解释:
- P值小于显著性水平: 如果计算得到的P值小于预先设定的显著性水平(通常为0.05),我们通常会认为结果是显著的。这意味着我们有足够的证据拒绝零假设,支持备择假设。
- P值大于显著性水平: 如果P值大于显著性水平,我们通常不能拒绝零假设。这表示我们没有足够的证据支持备择假设,结果不足以认为差异是显著的。
例如,如果进行了一项独立样本T检验,计算得到的P值为0.03,小于显著性水平0.05,我们通常会说结果是显著的,即有足够的证据拒绝零假设,接受备择假设。
实验材料
- 软件:SPSS 27.0
- 数据文件:某元音的F1与F2数据集(城市A与城市B)
2.操作步骤—独立样本T检验
1.导入数据到SPSS
- 打开SPSS。
- 选择
文件>导入数据,本文以Excel数据为例。
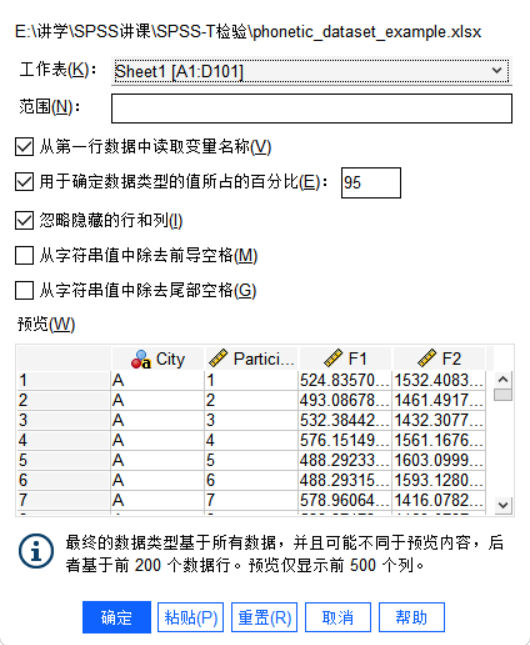
- 根据数据需求勾选相应的选项,点击
确定
2. 检查和清理数据
在进行任何分析之前,检查数据集是否正确导入,没有缺失值或错误数据。
- 在
变量视图中检查变量的属性,确保F1和F2被识别为数值变量。 - 在
数据视图中浏览数据,检查是否有任何异常值或输入错误。
3.正态性检验
- 点击分析>描述统计>探索
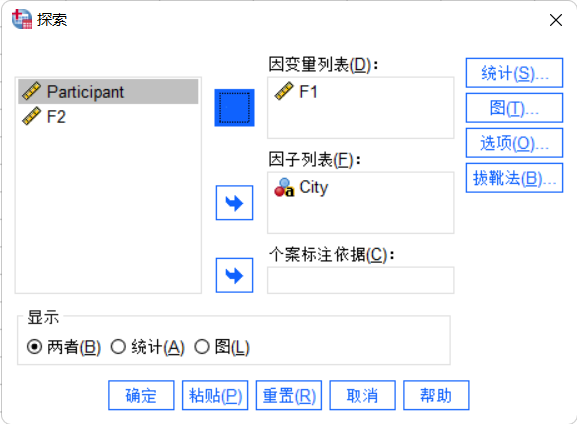
- T要求分组数据都满足正态分布,勾选相应的因子和因变量。
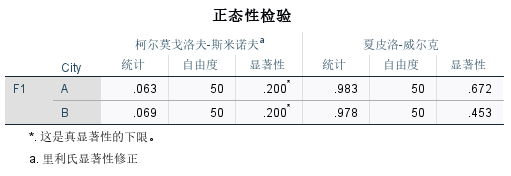
- 正态性检验结果:
- Kolmogorov-Smirnov检验(KW检验): 用于大样本,结果也显示在"Tests of Normality"表格中,观察统计量和显著性水平(p 值)。同样,如果 p 值大于 0.05,则接受正态性假设。
- Shapiro-Wilk检验(SW检验)::用于小样本,该检验的结果显示在"Tests of Normality"表格中,观察统计量和显著性水平(p 值)。如果 p 值大于 0.05,则接受正态性假设。
- 正态概率图(QQ图): 查看数据点是否落在直线上,直线表示正态分布。
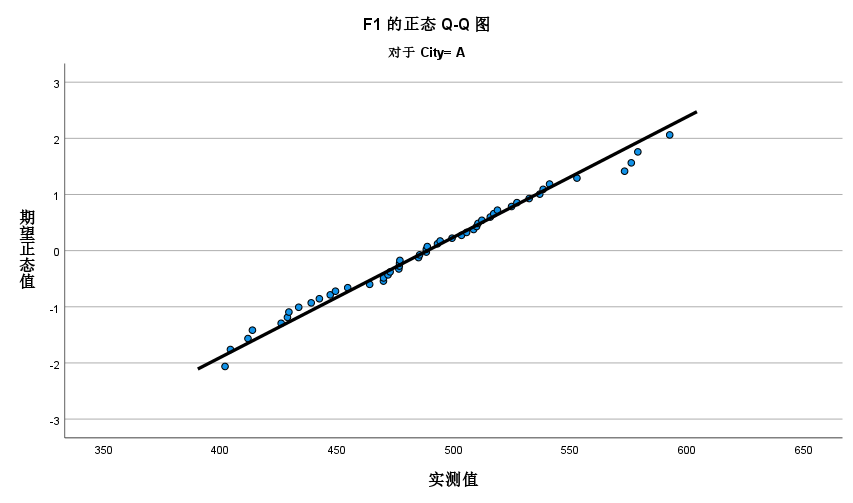
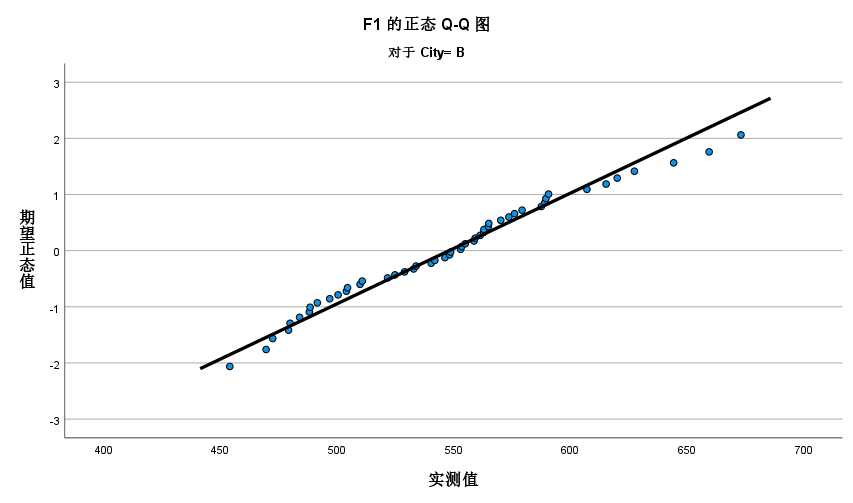
4.T检验
使用t检验分别比较不同城市的 F1和 F2的差异是否具有统计学意义:
- 选择
分析>比较平均值>独立样本T检验。
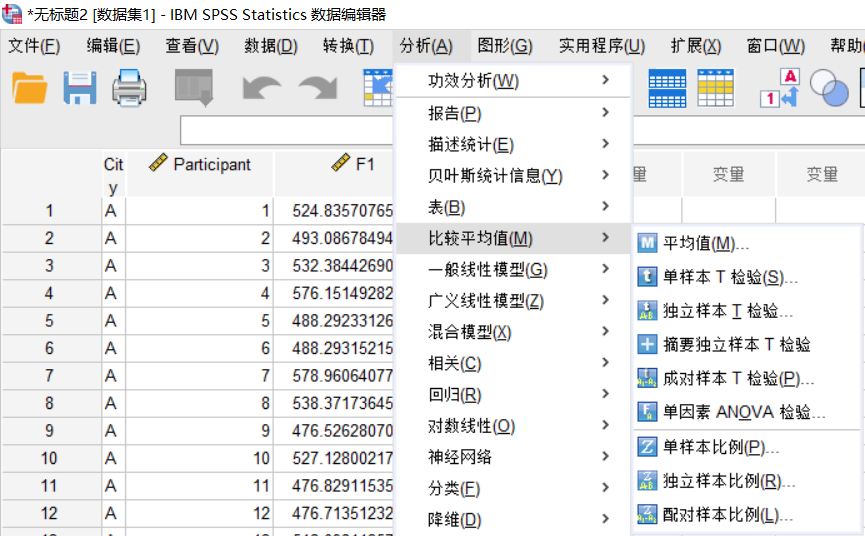
- 将
F1和F2设置为测试变量,City设置为分组变量。
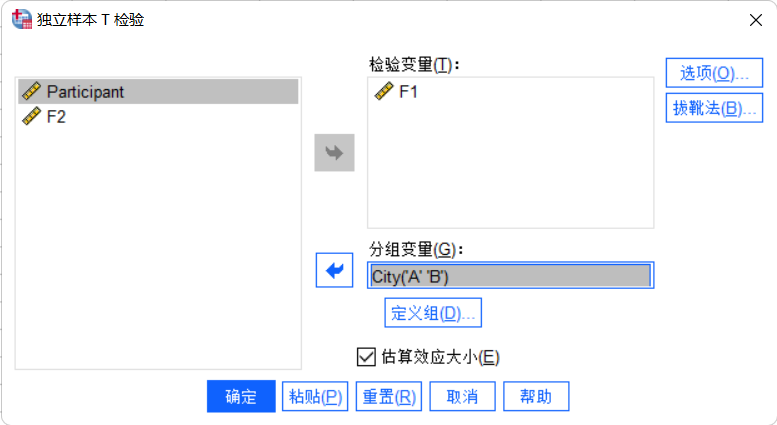
- 你需要为
City变量定义组,通常是输入城市标识符(如果你的数据中城市A和B使用别的名称,比如分别用1和2表示,那么这里就输入A和B)。
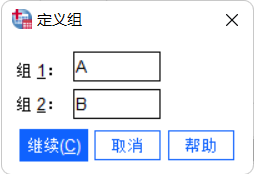
- 点击
确定以运行t检验。
分析与解释
描述性统计结果
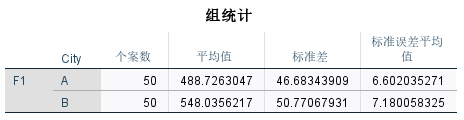
- 平均值(Mean) :平均值提供了变量F1和F2值的中心点。比较不同城市(如城市A和城市B)的平均值,可以初步了解两组间的差异。
- 标准差(Standard Deviation):标准差衡量数据分布的范围或离散程度。较小的标准差表明数据点紧密围绕平均值分布,而较大的标准差表明数据点分布更广。
通过观察这些描述性统计量,你可以对数据集的总体特征有一个基本了解,两个城市可能在元音发音的F1和F2声学特性上有差异。
t检验结果

- 莱文方差等同性检验:Levene 方差齐性检验,上文已经提及t检验要符合方差齐性,那么方差到底是否齐性呢?此处便是假设检验的结果,显著性即为p值,若p>0.05,认为方差齐性,即p<0.05,可认为方差不齐。 否则认为方差不齐。本题p=0.279,所以方差齐。
- 第一行,假定等方差,为满足方差齐性时的t检验结果;
- 第二行,不假定等方差,为不满足方差齐性时的t检验结果
此处,p=0.279>0.05,,故满足方差齐性,故至只看第一行结果。
- 平均值等同性t检验:此处是核心的假设检验结果。结果分为两行,分别“假定等方差”(方差齐)的t检验的结果,和“不假定等方差”(方差不齐)的检验结果,我们称之为t'检验(校正t检验,SPSS校正了自由度和t值)。若方差齐则采用t检验,看第一行t检验结果。若方差不齐,一般采用可以采用t'检验(SPSS校正自由度和t值),看第二行统计分析的结果。
- t值(T Statistic):t统计量是一个比率,它比较了两组间的差异与组内变异的大小。其值的绝对大小可以提供差异显著性的初步指示。
- p值(P Value/显著性/sig):p值是进行统计测试时最重要的结果之一。它表示在零假设为真的情况下,观察到的数据(或更极端情况)的概率。在大多数社会科学研究中,如果p值小于0.05,那么差异被认为是统计学上显著的,意味着两个城市的讲者在元音发音的声学特性上存在显著差异。
论文中如何叙述
在你的论文或报告中,描述性统计结果可以这样叙述:
(描述性统计分析显示),城市A的发音人在F1值上的平均值为XXX Hz(标准差为XX Hz),而在F2值上的平均值为YYY Hz(标准差为YY Hz)。相比之下,城市B的发音人在F1和F2值上的平均值分别为ZZZ Hz和WWW Hz,标准差分别为ZZ Hz和WW Hz。这些结果暗示了两个城市讲者的元音发音特性存在差异。
对于T检验的结果,可以这样叙述:
独立样本t检验显示,城市A和城市B的发音人在F1值上存在统计学上显著的差异(t=XX.XX,p<0.05)。同样,F2值的比较也揭示了两个城市之间的显著差异(t=YY.YY,p<0.05)。这些结果支持了我们的假设,即不同地区的讲者在元音发音的声学特性上存在显著差异。
在叙述结果时,确保以清晰和精确的方式报告统计数据,并解释这些结果对你的研究问题和假设的含义。
3.余论
构建合适的数据表结构
我们先来看两组数据表格式,这两组数据的内容是完全一致的,但是表格不同。
第一种:
| Group | Score |
|---|---|
| A | 78 |
| A | 82 |
| A | 88 |
| A | 75 |
| A | 90 |
| A | 85 |
| A | 88 |
| A | 92 |
| A | 80 |
| A | 86 |
| B | 70 |
| B | 65 |
| B | 72 |
| B | 68 |
| B | 78 |
| B | 75 |
| B | 80 |
| B | 68 |
| B | 82 |
| B | 77 |
第二种:
| GroupA | GroupB |
|---|---|
| 78 | 70 |
| 82 | 65 |
| 88 | 72 |
| 75 | 68 |
| 90 | 78 |
| 85 | 75 |
| 88 | 80 |
| 92 | 68 |
| 80 | 82 |
| 86 | 77 |
在前面的操作步骤中,我们在T检验过程中需要勾选哪一列是分组变量,但是如果采用第二种格式,我们就无法勾选变量,但第一种数据就很好在SPSS中使用。
在SPSS中进行数据分析时,通常更适合使用长格式(Long Format)的数据,即每个观测在一个单独的行中,并且包含一个指示组别的变量。因此,第一组数据更符合SPSS的分析要求,每个观察值占据数据表中的一行,并且每个变量有自己的列。有一列指示该行中包含的变量类型,然后另一行表示该变量的值。每行包含单个变量的单个观察值。它仍然是一个整齐的数据集,但信息以很长的格式存储。 将数据组织成长格式有助于使用SPSS进行各种统计分析和建模。
假设有一项实验研究了两组学生(组别A和组别B)在不同时间点的测试成绩。长格式的数据表可能如下所示:
| 学生ID | 组别 | 时间点 | 成绩 |
|---|---|---|---|
| 1 | A | 1 | 78 |
| 1 | A | 2 | 82 |
| 1 | A | 3 | 88 |
| 2 | B | 1 | 70 |
| 2 | B | 2 | 65 |
| 2 | B | 3 | 72 |
每一行代表一个学生在特定时间点的测试成绩,学生ID用于区分不同的学生,组别和时间点则用于区分不同的组别和测量时间点。
数据分析的好习惯——先画散点图
观察散点图是一种常见的方法,用于初步了解变量之间的关系,并判断是否适合进行线性分析。
.png)
- 线性关系: 如果散点图呈现大致的直线形状,那么可能存在线性关系,适合进行线性回归分析。线性关系意味着一个变量的变化与另一个变量成正比或反比。
- 非线性关系: 如果散点图显示曲线、曲面或其他形状,可能存在非线性关系,此时可能需要考虑非线性回归模型。非线性关系可能包括二次方程、指数关系等。
- 离群值: 注意是否存在离群值,因为离群值可能对线性回归的假设产生不良影响。可以考虑对数据进行清理或使用鲁棒的回归方法。
- 变量的变换: 在观察散点图的过程中,你可能会注意到数据不满足线性回归的假设,但通过对变量进行变换(如对数、平方根等),可以使数据更接近线性。
练习
以下是一个研究案例,其中课上提供的数据集为虚构,仅用于技术练习。
研究背景
研究主题:辅音脱落现象在快速语流中的频率和条件
研究目的:探索在自然快速语流中,特定辅音(例如,/t/和/d/)脱落的频率,以及这种脱落现象与语言环境(如前后音素的类型)和说话者特征(如年龄、性别)的关系。
参与者
- 60名母语为英语的成年人,平均分为三个年龄组,每组20人:青少年(13-19岁)、中年(35-50岁)、老年(65岁以上)。
- 性别在每个年龄组内平均分布。
数据收集
- 记录参与者阅读一段包含大量特定辅音的文本,并在自然快速的语速下对话,以此收集语音样本。
- 对语音样本进行分析,特别关注/t/和/d/辅音在不同环境下的脱落情况。
数据集结构
假设数据集如下:
| 参与者ID | 年龄组 | 性别 | 辅音脱落次数_t | 辅音脱落次数_d | 语言环境类型 | 阅读文本长度 | 说话速度 |
|---|---|---|---|---|---|---|---|
| 1 | 青少年 | 男 | 44 | 47 | 前辅音 | 392 | 167 |
| 2 | 青少年 | 男 | 3 | 39 | 前辅音 | 923 | 121 |
| 3 | 青少年 | 男 | 36 | 23 | 后元音 | 672 | 188 |
| 4 | 青少年 | 男 | 12 | 1 | 后元音 | 751 | 187 |
| …… | …… | …… | …… | …… | …… | …… | …… |
需要解决的问题
- 对不同性别的参与者,对辅音脱落情况进行描述性分析。
- 分析/t/和/d/辅音在不同性别情况下的差异。